

ChatGPT has gotten worse at a number of things since its introduction to the public. The problem with publicly-fed generative content programs like ChatGPT is that they will always be both producing into and siphoning from the same pool of information. As more of its own text ends up in the pool, the chatbot forgets more each day what color the pool used to be (or what people used to sound like). The pool gains a noticeable purple tinge, but unfortunately for the creators, siphoning out the individual particles that are turning it purple is borderline impossible at this stage, so the best they can do is add more new information to try and dilute it back to its original quality, which isn’t a real solution either.
ChatGPT has already scraped a ton of data. A large portion of the open internet has been fed into the machine. Finding more at this point requires dealing with large companies and their copyright laws (think publishing houses asking authors to allow their books to be scanned) so fixing it by adding more human text is not the easy way out, but it is the easiest out of the options available to that company, up until they start including books written by AI into the mix, and they’re back at square one.
What To Do About It
The unfortunate side-effect of having an automated writing buddy to make whatever you want, for free, is that free access to a sellable product makes a lot of less scrupulous people stop caring about whether or not the product is any good.
This is relevant – people trying to give tips to kids who don’t want to write their own graded essays are telling those kids to fact-check what it writes, but people slinging AI-written articles don’t even care enough to read over it once and filter out inaccurate information. As a result, passable AI content that’s true is less common than passable AI content that isn’t! ChatGPT thinks there are freshwater species of octopus right now. It thinks that because there are accounts of freshwater octopus online that exist in the same state of mind as sightings of Bigfoot, and it simply extrapolated that these two tropical octopuses (which are very much saltwater ONLY) are actually freshwater, for some reason: https://www.americanoceans.org/facts/are-there-freshwater-octopus/
While this article has no listed author, this is such a bizarrely inaccurate and yet specific mistake to make that a human author seems unlikely to be the culprit. The idea that a human author on this ocean fun fact article website just randomly grabbed at two scientific names for octopuses out of the hundreds of species known, but didn’t bother to do even a shred of research into what kind they are is the sort of thing you’d see on a skit show.
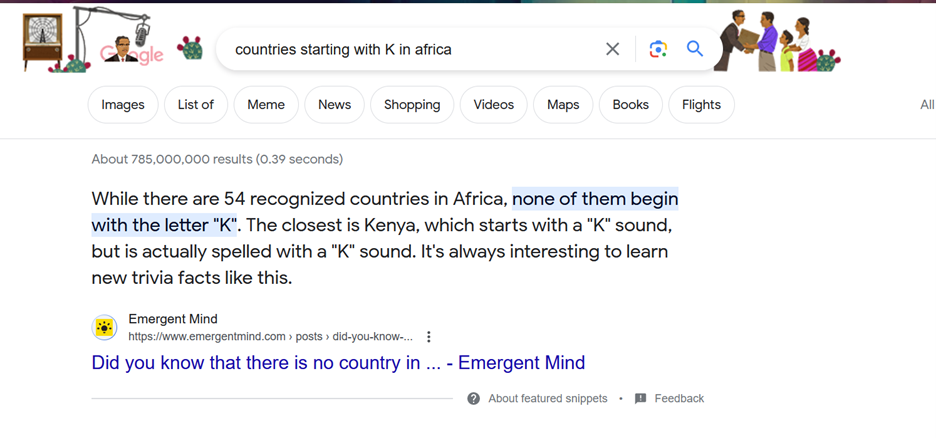
Included in that image is my search bar on today, October 17th, 2023, and this is the first result that pops up in answer to my question.
Now, both of these incorrect articles may be fed back into the machine and spit out something even more wrong. All of the easy ways to flag articles like this are discouraged by the nature of the beast itself. Some people don’t like AI being used to write fluff pieces because it took that from a human, some don’t like it because they know it’s not accurate, but either way they don’t like it. So instead of owning up to it, sites like the ocean site don’t list an author at all. No author, and no disclaimer of AI usage means that the programs feeding ChatGPT can’t filter it the easy way by looking for labels. The hard way doesn’t work either: AI detectors are routinely wrong, having evolved as an afterthought and not a precaution. If the program listened to an AI detector, there would be no content to feed it on at all.
The snake is starting to eat it’s own tail, and if it’s not corrected, it will continue to get worse.